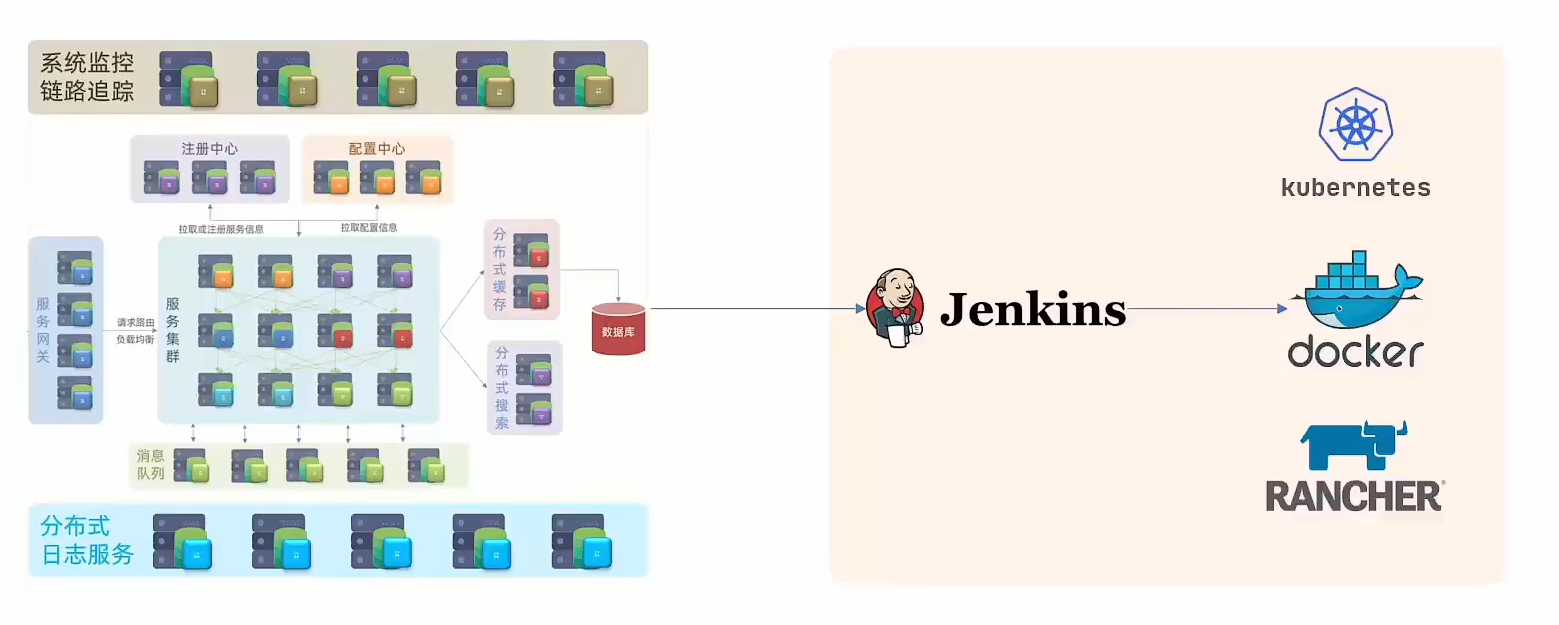
SpringCloud
SpringCloud
服务架构
单体架构
- 将业务的所有功能集中在一个项目中开发,打成一个包部署
优点
- 架构简单
- 部署成本低
缺点
- 耦合度高
分布式架构
- 根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务
优点
- 降低服务耦合
- 有利于服务升级拓展
问题
- 服务拆分粒度如何
- 服务集群地址如何维护
- 服务之间如何实现远程调用
- 服务健康状态如何感知
认识微服务
- 微服务是一种经过良好架构设计的分布式架构方案
特征:
- 单一职责:微服务拆分粒度更小,每一个服务对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露接口需求
- 自治:团队、技术、数据、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
服务拆分
- 不同微服务,不重复开发相同业务
- 微服务数据独立,不访问其他微服务的数据库
- 微服务可将自身的业务暴露为接口,供其他微服务调用
- 注册RestTemplate
1 | |
- 服务远程调用RestTemplate
1 | |
Eureka
服务调用关系
- 服务提供者:暴露接口给其他微服务调用
- 服务消费者:调用其他微服务提供的接口
- 提供者与消费者角色是相对的
- 一个服务可以同时是服务提供者和服务消费者
作用
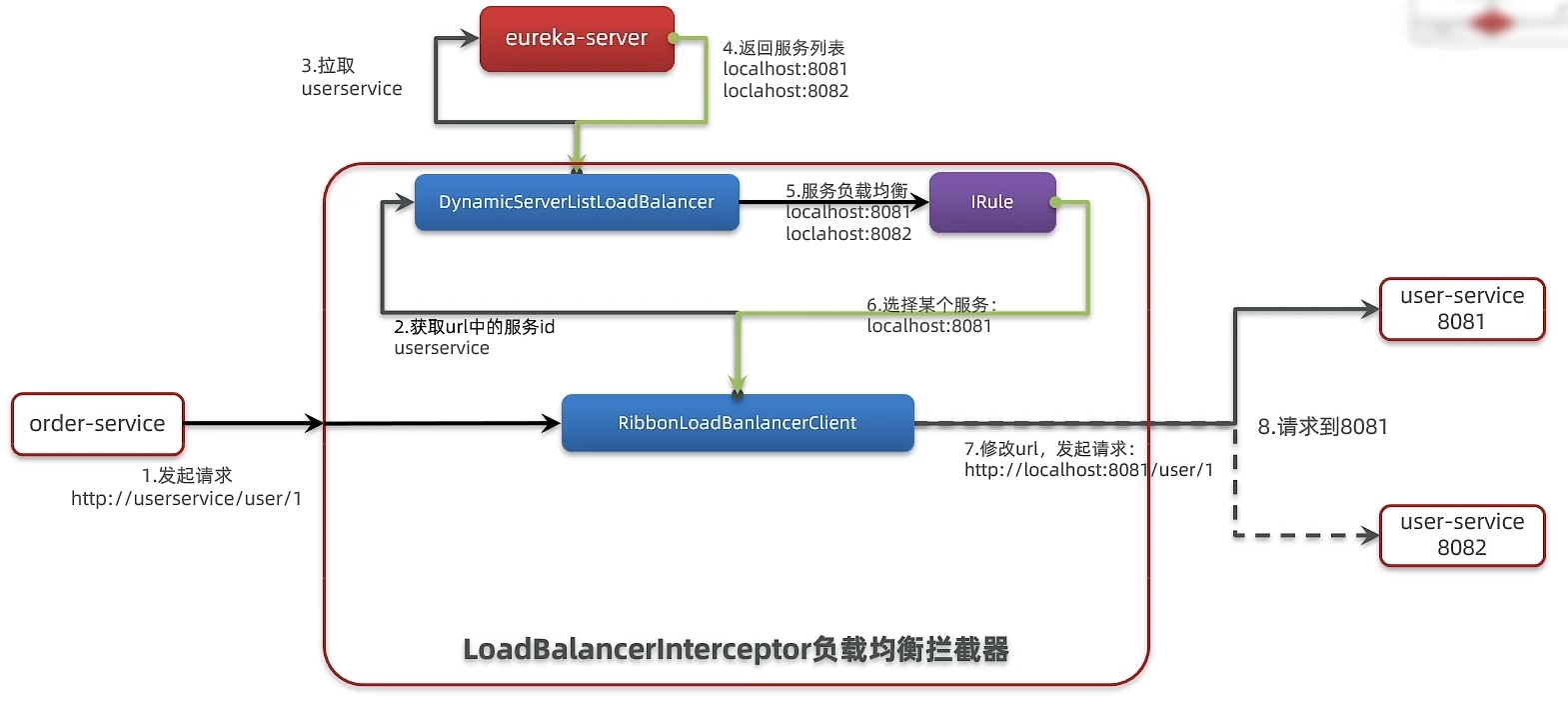
- 消费者如何获取服务提供者具体信息?
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
- 如果有多个服务提供者,消费者如何选择?
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
- 消费者如何感知服务提供者健康状态?
- 服务提供者每隔30s向EurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者可以拉取到最新的信息
总结
- EurekaServer:服务端,注册中心
- 记录服务信息
- 心跳监控
- EurekaClient:客户端
- Provider:服务提供者
- 注册自己的信息到EurekaServer
- 每隔30s向EurekaServer发送心跳
- consumer:服务消费者
- 根据服务名称从EurekaServer拉取服务列表
- 基于服务列表做负载均衡,选中一个微服务后发起远程调用
- Provider:服务提供者
注册中心
- 搭建EurekaServer
- 创建项目,引入依赖
1 | |
- 编写启动类,添加@EnableEurekaServer注解
1 | |
- 添加application.yml文件
1 | |
- 服务注册
- 引入依赖
1 | |
- 在application.yml文件,编写配置
1 | |
- 服务发现
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
- 给RestTemplate添加@LodeBalanced注解
1 | |
- 用服务提供者的服务名称远程调用
Ribbon
负载均衡
规则
- 规则接口是IRule
- 默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器,它是Ribbon默认的负载均衡规则 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略:(1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加(2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器 |
| RandomRule | 随机选择一个可用的服务器 |
| RetryRule | 重试机制的选择逻辑 |
自定义方式
- 代码方式:配置灵活,但修改时需要重新打包发布
- 配置方式:直观、方便,无需重新打包发布,但无法做全局配置
通过定义IRule实现可以修改负载均衡规则,有两种方式:
- 代码方式:在order-service中的OrderApplication类中,定义一个新的IRule
1 | |
- 配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则
1 | |
饥饿加载
- Ribbon默认采用懒加载,即第一次访问时会创建LoadBalanceClient,请求时间会很长
- 饥饿加载则会在项目启动时创建,降低第一次访问的耗时
1 | |
Nacos
- 引入依赖
- 在cloud-demo父工程的pom文件中的
<dependencyManagement>中引入SpringCloudAlibaba的依赖
1 | |
- 在user-service和order-service中的pom文件中引入nacos-discovery依赖
1 | |
- 配置nacos地址
- 在user-service和order-service的application.yml中添加nacos地址
1 | |
服务多级存储模型
修改user-service的application.yml文件,添加集群配置:
1 | |
- 一级是服务,例如userservice
- 二级是集群,例如杭州或上海
- 三级是实例,例如杭州机房的某台部署了userservice的服务器
设置实例的集群属性
- 修改application.yml文件,添加spring.cloud.nacos.discovery.cluster-name属性
NacosRule负载均衡
- 优先选择同集群的服务实例列表
- 本地集群找不到提供者,才去其它集群寻找,并且会报警告
- 确定了可用实例列表后,再采取负载均衡挑选实例
服务实例的权重设置
- 在Nacos控制台可以设置实例的权重值,首先选中实例后面的编辑按钮
- 将权重设置为0.1,测试可以发现8081被访问到的频率大大降低
- Nacos控制台可以设置实例的权重值,0~1之间
- 同集群内的多个实例,权重越高被访问的频率越高
- 权重设置为0则完全不会被访问
环境隔离
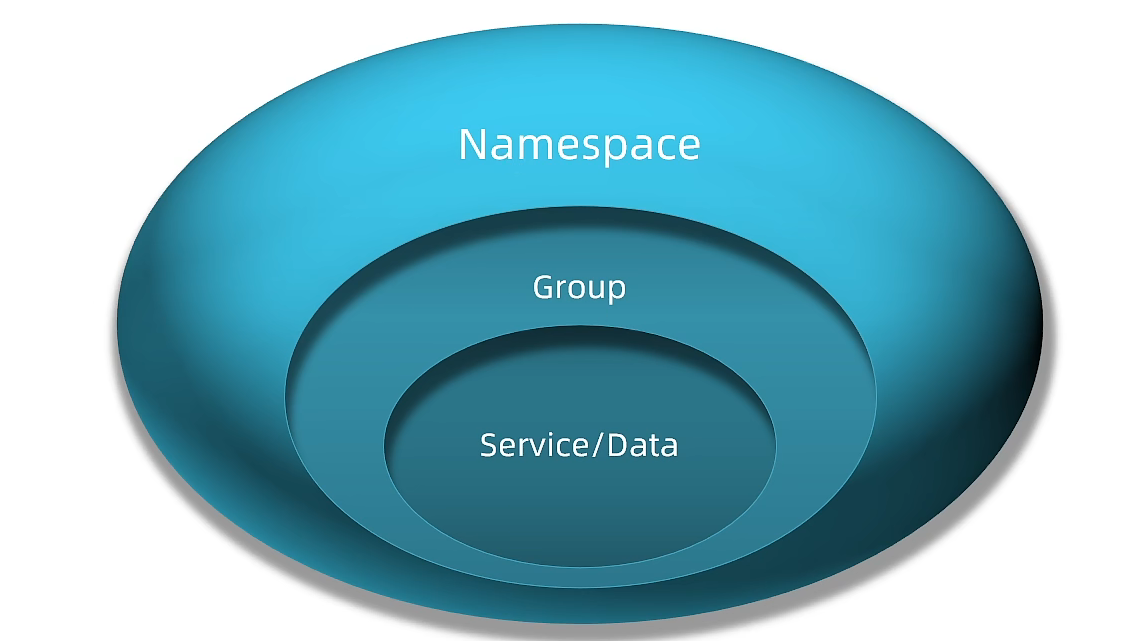
- namespace用来做环境隔离
- 每个namespace都有唯一id
- 不同namespace下的服务不可见
1 | |
端口被占用问题解决
- 键盘输入(win+r),接着在运行对话框中输入“cmd”,进入命令窗口
- 输入netstat -ano|findstr “8080”,回车
- 接着输入tasklist|findstr"3516",回车得到占用8080端口的进程
- 打开“任务管理器”,定位改进程,然后结束进程,8080端口占用被取消
- 或者使用命令关闭:taskkill -PID 3516 -F
Nacos和Eureka对比
- 共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
- 区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送方式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos配置管理
统一配置管理
- 在Nacos中添加配置信息
- 在弹出表单中填写配置信息
配置获取
- 在Nacos中添加配置文件
- 在微服务中引入Nacos的config依赖
- 在微服务中添加bootstrap.yml,配置Nacos地址、当前环境、服务名称、文件后缀名
配置热更新
- 通过@Value注解注入,结合@RefreshScope来刷新
- 通过@ConfigurationProperties注入,自动刷新
多环境配置共享
多种配置的优先级
-
服务名-profile.yaml > 服务名称.yaml > 本地配置
当前环境配置
nacos中的配置 本地配置
微服务会从Nacos读取的配置文件
- [服务名]-[spring.profile.active].yaml,环境配置
- [服务名].yaml,默认配置,多环境共享
Nacos集群搭建
集群结构图
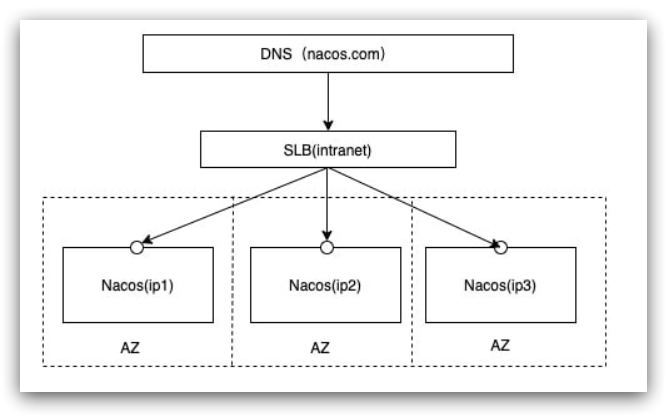
三个nacos节点的地址:
| 节点 | ip | port |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
搭建集群
搭建集群的基本步骤:
- 搭建数据库,初始化数据库表结构
- 下载nacos安装包
- 配置nacos
- 启动nacos集群
- nginx反向代理
初始化数据库
首先新建一个数据库,命名为nacos,而后导入下面的SQL:
1 | |
配置Nacos
目录说明:
- bin:启动脚本
- conf:配置文件
进入nacos的conf目录,修改配置文件cluster.conf.example,重命名为cluster.conf
添加内容:
1 | |
然后修改application.properties文件,添加数据库配置
1 | |
启动
将nacos文件夹复制三份,分别命名为:nacos1、nacos2、nacos3
分别修改三个文件夹中的application.properties
nacos1:
1 | |
nacos2:
1 | |
nacos3:
1 | |
然后分别启动三个nacos节点:
1 | |
Nginx反向代理
修改conf/nginx.conf文件,配置如下:
1 | |
而后在浏览器访问:http://localhost/nacos即可。
代码中application.yml文件配置如下:
1 | |
优化
-
实际部署时,需要给做反向代理的nginx服务器设置一个域名,这样后续如果有服务器迁移nacos的客户端也无需更改配置.
-
Nacos的各个节点应该部署到多个不同服务器,做好容灾和隔离
Feign
基于Feign远程调用
-
Fegin是一个声明式的http客户端
-
作用是优雅的实现http请求的发送
- 引入依赖
1 | |
- 在order-service的启动类添加注解开启Feign的功能
1 | |
- 编写Feign客户端
1 | |
主要是基于SpringMVC的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
自定义配置
Feign运行自定义配置来覆盖默认配置
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| 类型 | 作用 | 说明 |
| feign. Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign. Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
方式一:配置文件方式
- 全局生效
1 | |
- 局部生效
1 | |
方式二:java代码
声明一个Bean
1 | |
- 如果是全局配置,则把它放到@EnableFeignCients注解中
1 | |
- 如果是局部配置,则把它放到@FeignClient注解中
1 | |
性能优化
Feign底层客户端实现
- URLConnection:默认实现,不支持连接池
- Apache HttpClient:支持连接池
- OKHttp:支持连接池
优化Feign性能主要包括
-
使用连接池代替默认的URLConnection
-
日志级别,最好用basic或none
- 引入依赖
1 | |
- 配置连接池
1 | |
最佳实践
方式一(继承):给消费者的FeignClient和提供者的controller定义统一的父接口作为标准
方式二(抽取):将FeignClient抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用
实现最佳实践方式二的步骤
- 首先创建一个module,命名为feign-api,然后引入feign的starter依赖
1 | |
-
将order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中
-
在order-service的pom文件中中引入feign-api的依赖
1 | |
-
修改order-service中所有与上述三个组件有关的import部分,改成导入feign-api中的包
-
重启测试
Gateway网关
网关作用
- 身份认证和权限校验
- 服务路由、负载均衡
- 请求限流
在SpringCloud中网关的实现包括两种
- gateway
- zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateWay则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能
搭建网关
- 创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖
1 | |
- 编写路由配置及nacos地址
1 | |
路由配置
- 路由id:路由唯一的标示
- 路由目标(url):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则
- 路由过滤器(filters):对请求或响应做处理
路由断言工厂
-
在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件
-
例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来处理的 -
像这样的断言工厂在SpringCloudGateway还有十几个
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
-
PredicateFactory的作用是什么?
读取用户定义的断言条件,对请求做出判断
-
Path=/user/**是什么含义?
路径是以/user开头的就以为是符合的
路由的过滤器配置
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理
Spring提供了31种不同的路由过滤器工厂
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
在gateway中修改application.yml文件,给userservice的路由添加过滤器
1 | |
- 过滤器的作用?
- 对路由的请求或响应做加工处理,比如添加请求头
- 配置在路由下的过滤器只对当前路由的请求生效
- defaultFilters的作用?
- 对所有路由都生效的过滤器
全局过滤器
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewanFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
实现GlobalFilter接口
1 | |
过滤器链执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器
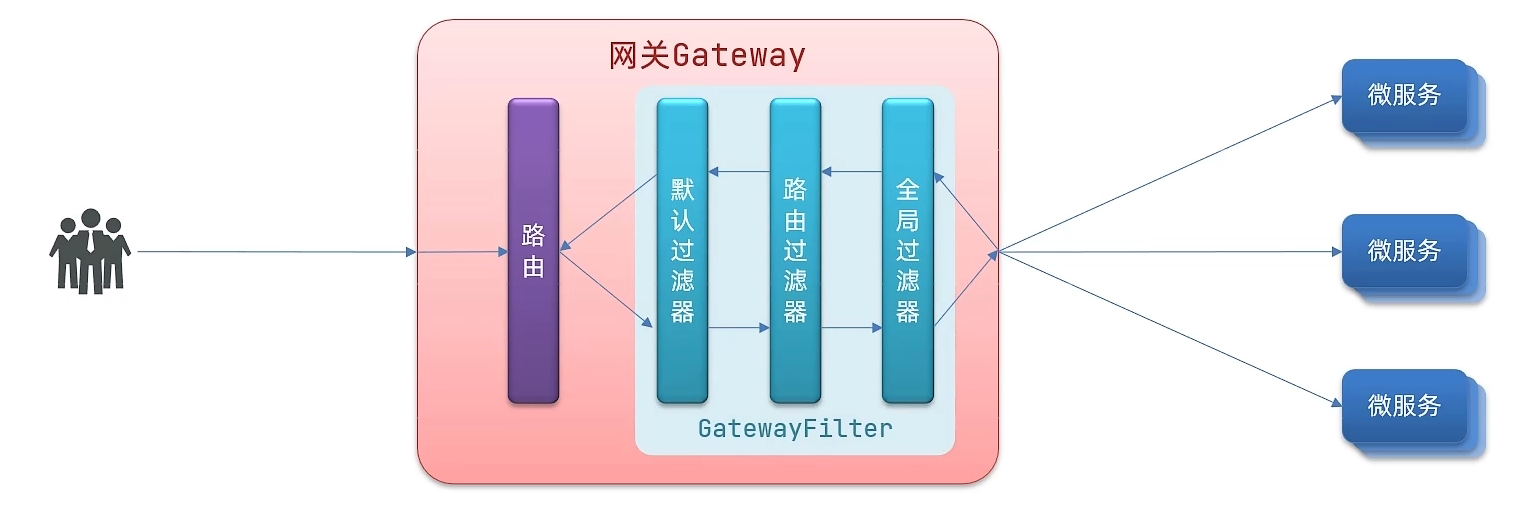
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行
路由过滤器、DefaultFilter、GlobalFilter的执行顺序?
- order值越小,优先级越高
- 当order值一样时,顺序是DefaultFilter最先,然后是局部路由过滤器,最后是GlobalFilter
网关的cors跨域配置
跨域:域名不一致就是跨域
- 域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
- 域名相同,端口不同:localhost:8080和localhost8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
Docker
什么是Docker
Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题?
- Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker如何解决开发、测试、生产环境有差异的问题
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术
- 可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动、移除都可以通过一行命令完成、方便快捷
Docker与虚拟机
虚拟机(virtual machine)是在操作系统中模拟硬件设备,然后运行另一个操作系统,比如在Windows系统里面运行Ubuntu系统,这样就可以运行任意的Ubuntu应用了
| 特性 | Docker | 虚拟机 |
|---|---|---|
| 性能 | 接近原生 | 性能较差 |
| 硬盘占用 | 一般为MB | 一般为GB |
| 启动 | 秒级 | 分钟级 |
Docker与虚拟机的差异
- Docker是一个系统进程;虚拟机时在操作系统中的操作系统
- Docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
Docker架构
镜像和容器
镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器进程做隔离,对外不可见
Docker和DockerHub
-
DockerHub:DockerHub是一个官方的Docker镜像的托管平台。这样的平台称为Docker Registry
Docker架构
Docker是一个CS架构的程序,由两部分组成
- 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
- 客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令
镜像命令
- 镜像名称一般分两部分组成:[repository]:[tag]
- 没有指定时,默认时latest,代表最新版本的镜像
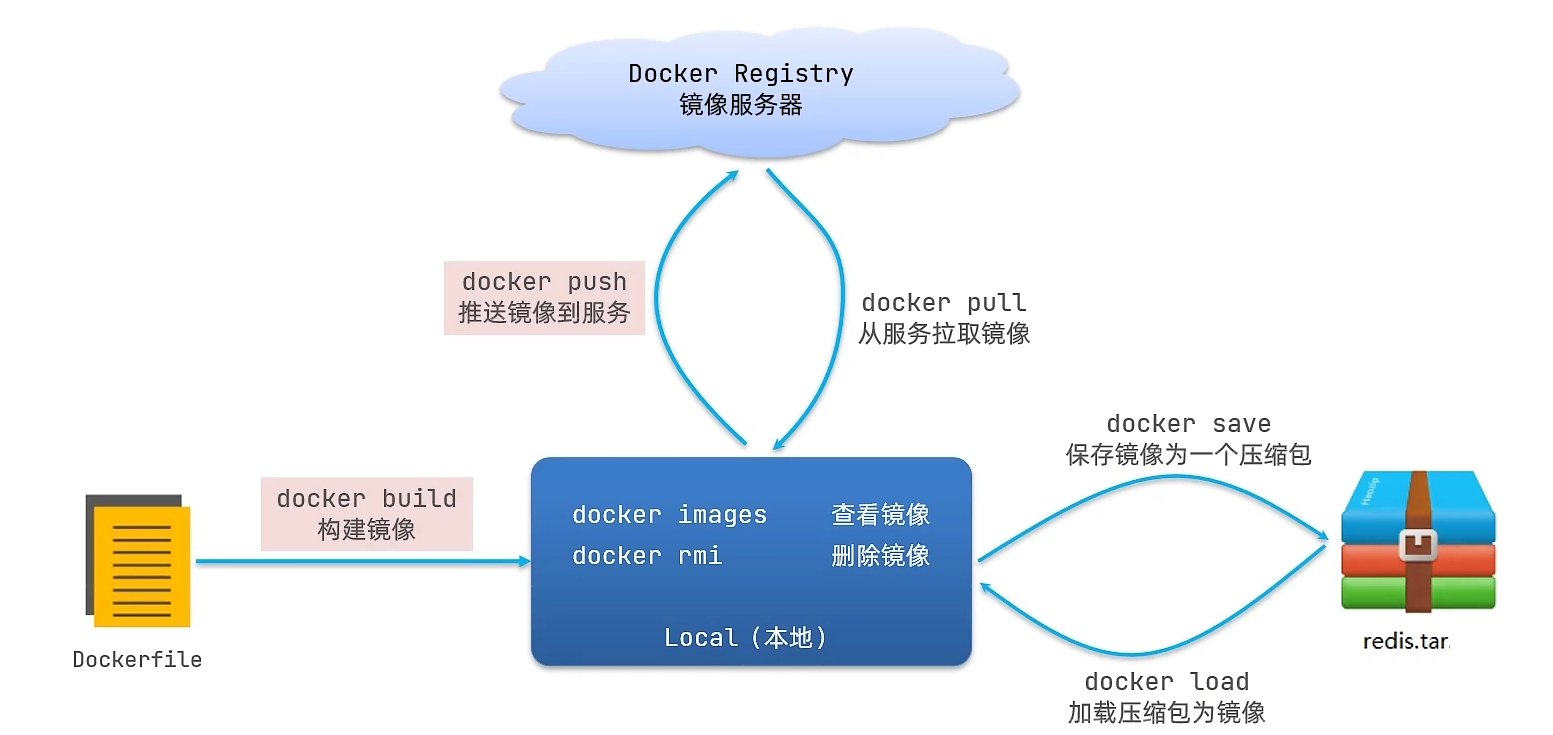
镜像操作有哪些?
- docker images
- docker rmi
- docker pull
- docker push
- docker save
- docker load
容器命令
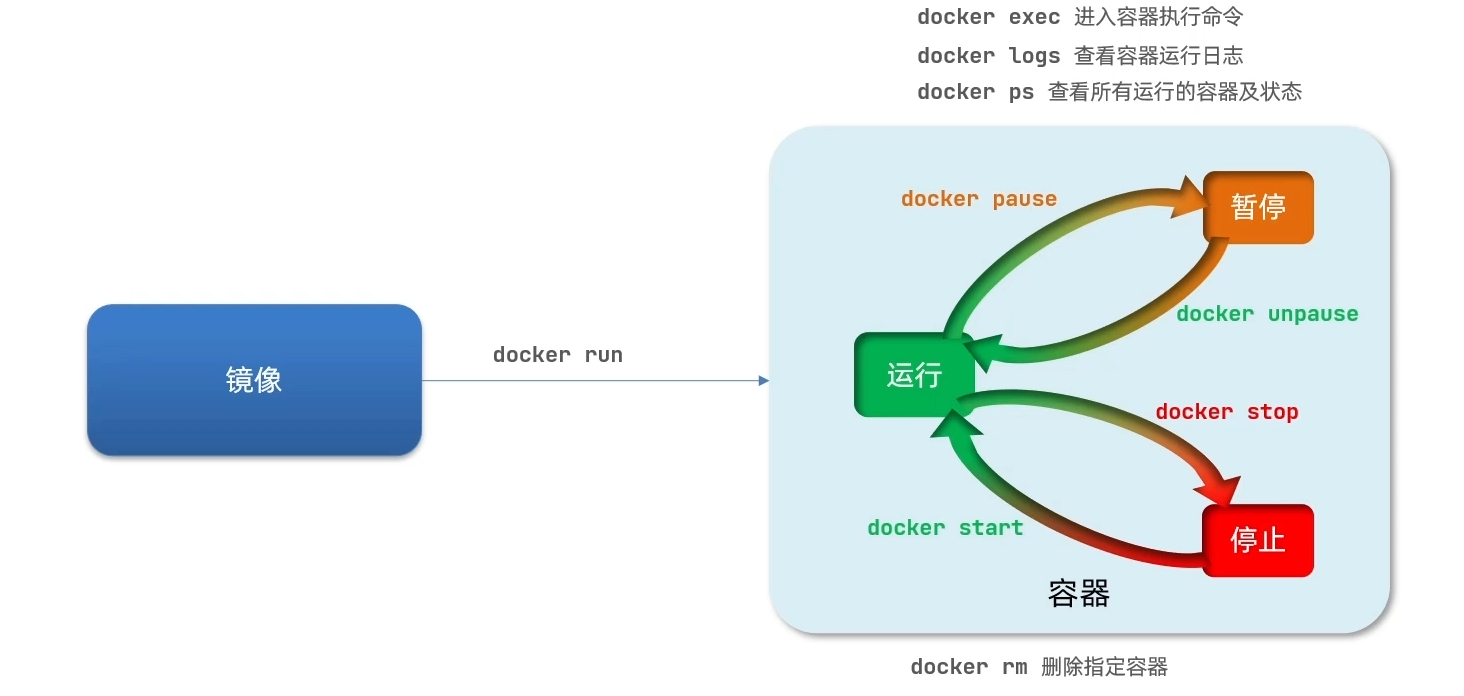
案例一
1 | |
- docker run:创建并运行一个容器
- –name:给容器起一个名字,比如mn
- -p:将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
- -d:后台运行容器
- nginx:镜像名称,例如nginx
docker run命令的常见参数有哪些?
- –name:指定容器名称
- -p:指定端口映射
- -d:让容器后台运行
查看容器日志命令
- docker logs
- 添加-f参数可以持续查看日志
查看容器状态
- docker ps
案例二
1 | |
- docker exec:进入容器内部,执行一个命令
- -it:给当前进入的容器创建一个标准输入、输出终端,允许与容器交互
- mn:要进入的容器的名称
- bash:进入容器后执行的命令,bash是一个linux终端交互命令
进入nginx的HTML所在目录
1 | |
修改index.html的内容
1 | |
查看容器状态
- docker ps
- 添加-a参数查看所有状态的容器
删除容器
- docker rm
- 不能删除运行中的容器,除非添加-f参数
进入容器
- docker exec -it [容器名] [要执行的命令]
- exec命令可以进入容器修改文件,但在容器内修改文件是不推荐的
数据卷命令
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录
1 | |
- create:创建一个volume
- inspect:显示一个或多个volume信息
- ls:列出所有的volume
- prune:删除未使用的volume
- rm:删除一个或多个指定对volume
挂载案例一
- 创建容器并挂载数据卷到容器内的HTML目录
1 | |
- 进入html数据卷所在位置,并修改HTML内容
1 | |
数据卷挂载方式
- -v volumeName: /targetContainerPath
- 如果容器运行时volume不存在,会自动被创建出来
挂载案例二
容器不仅仅可以挂载数据卷,也可以直接挂载到宿主机目录上
- 带数据卷模式:宿主机目录 --> 数据卷 —> 容器内目录
- 直接挂载模式:宿主机目录 —> 容器内目录
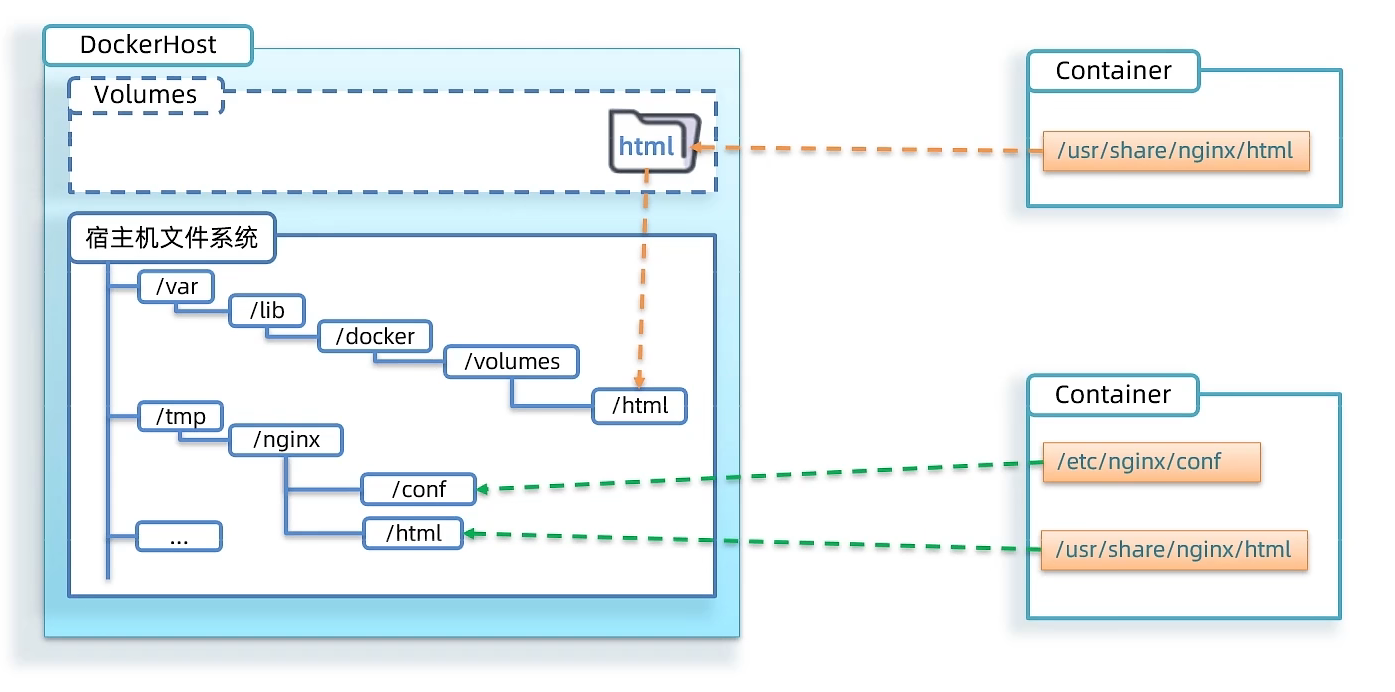
docker run的命令中通过 -v 参数挂载文件或目录到容器
- -v volume名称:容器内目录
- -v 宿主机文件:容器内文件
- -v 宿主机目录:容器内目录
自定义镜像
镜像结构
- 镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成
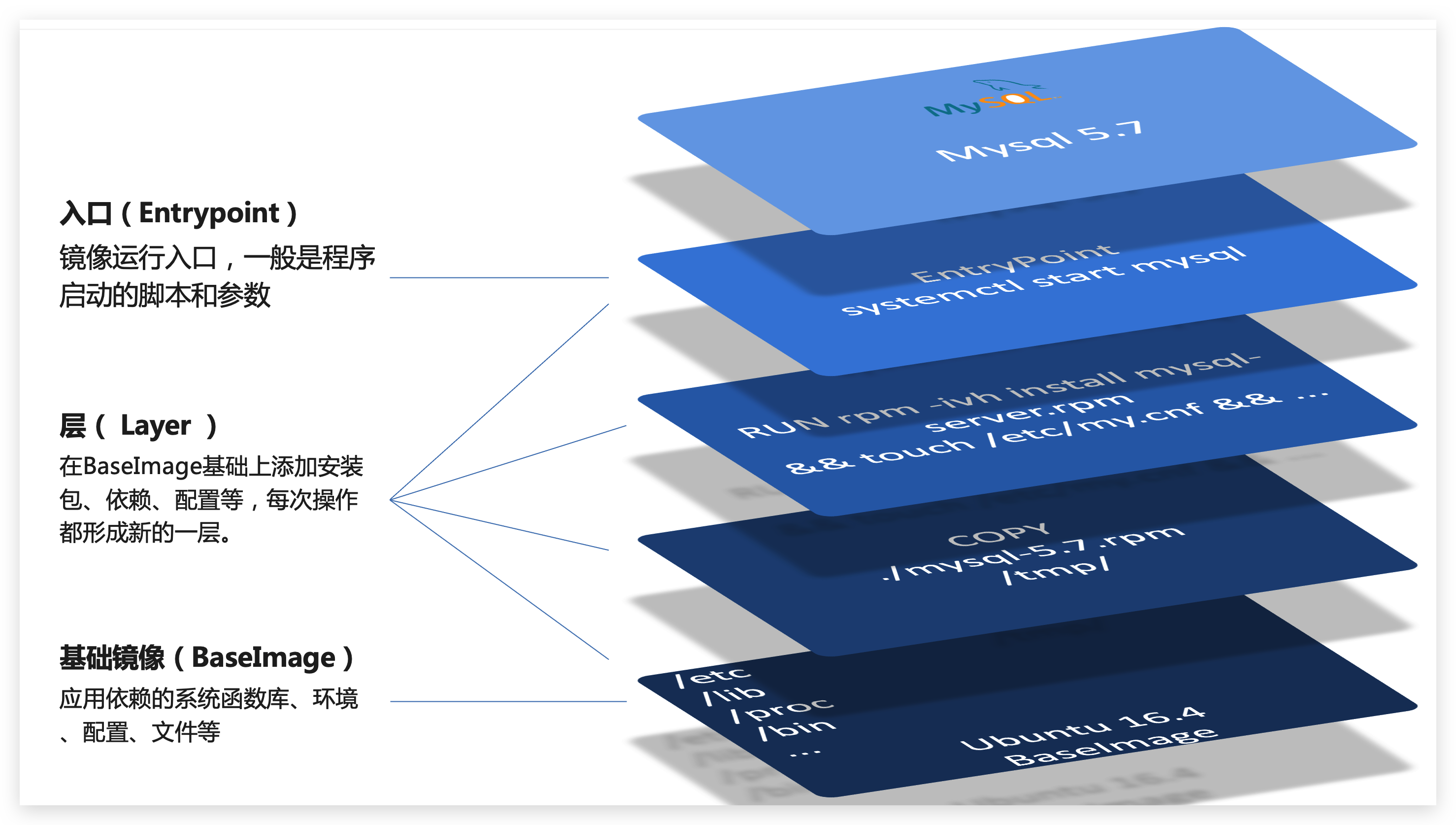
镜像是分层结构,每一层称为一个Layer
- BaseImage层:包含基本的系统函数库、环境变量、文件系统
- Entrypoint:入口,是镜像中应用启动的命令
- 其它:在BaseImage基础上添加依赖、安装程序、完成整个应用的安装和配置
Dockerfile
Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer
| 指令 | 说明 | 示例 |
|---|---|---|
| FROM | 指定基础镜像 | FROM centos:6 |
| ENV | 设置环境变量,可在后面指令使用 | ENV key value |
| COPY | 拷贝本地文件到镜像的指定目录 | COPY ./mysql-5.7.rpm /tmp |
| RUN | 执行Linux的shell命令,一般是安装过程的命令 | RUN yum install gcc |
| EXPOSE | 指定容器运行时监听的端口,给镜像使用者看 | EXPOSE 8080 |
| ENTERPOINT | 镜像中应用的启动命令,容器运行时调用 | ENTRYPOINT java -jar xx.jar |
- Dockerfile的本质是一个文件,通过指令描述镜像的构建过程
- Dockerfile的第一行必须是FROM,从一个基础镜像来构建
- 基础镜像可以是基本操作系统,如Ubuntu。也可以是制作好的镜像,如java:8-alpine
DockerCompose
初识Compose
- DockerCompose可以基于Compose文件快速的部署分布式应用,无需手动一个个创建和运行容器
- Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行
1 | |
DockerCompose作用
- 快速部署分布式应用,无需一个个微服务构建镜像和部署
Docker镜像仓库
镜像仓库(Docker Registry)有公共的和私有的两种形式
- 公共仓库:例如Docker官方的Docker Hub
- 用户可以在本地搭建私有Docker Registry。企业镜像最好是采用私有Docker Registry实现
简化版镜像仓库
Docker官方的Docker Registry是一个基础版本的Docker镜像仓库,具备仓库管理的完整功能,但是没有图形化界面。
搭建方式比较简单,命令如下:
1 | |
命令中挂载了一个数据卷registry-data到容器内的/var/lib/registry 目录,这是私有镜像库存放数据的目录。
访问http://YourIp:5000/v2/_catalog 可以查看当前私有镜像服务中包含的镜像
带有图形化界面版本
使用DockerCompose部署带有图象界面的DockerRegistry,命令如下:
1 | |
配置Docker信任地址
我们的私服采用的是http协议,默认不被Docker信任,所以需要做一个配置:
1 | |
在私有镜像仓库推送或拉取镜像
推送镜像到私有镜像服务必须先tag,步骤如下:
- 重新tag本地镜像,名称前缀为私有仓库的地址:192.168.150.101:8080/
1 | |
- 推送镜像
1 | |
- 拉取镜像
1 | |
RabbitMQ
初识MQ
同步调用存在的问题
- 耦合度高:每次加入新的需求,都要修改原来的源码
- 性能下降:调用者需要等待服务提供者响应,如果调用链过长则响应时间等于每次调用的时间之和
- 资源浪费:调用链中的每个服务在等待响应过程中,不能释放请求占用的资源,高并发场景下会极度浪费系统资源
- 级联失败:如果服务提供者出现问题,所有调用方都会跟着出现问题,如同多米诺骨牌一样,迅速导致整个微服务器故障
同步调用的优缺点
优点
- 时效性较强,可以立即得到结果
缺点
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败问题
异步通信的优缺点
优点
- 耦合度低
- 吞吐量提升
- 故障隔离
- 流量削峰
缺点
- 依赖于Broker的可靠性、安全性、吞吐能力
- 架构复杂,业务没有明显的流程线,不好追踪管理
MQ常见技术
MQ(MessageQueue),消息队列,字面上看是存放消息的对列。就是事件驱动架构中的Broker
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
RabbitMQ概述和部署
- RabbitMQ是基于Erlang语言开发的开源消息通信中间件
- 官网
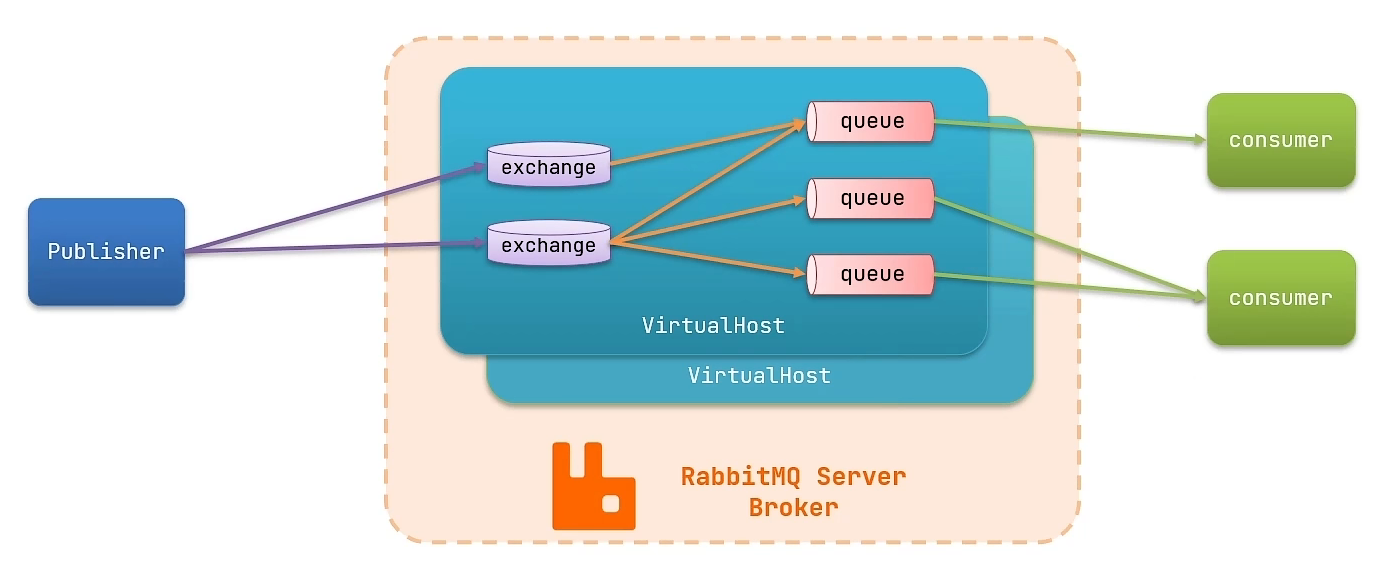
RabbitMQ概念
- channel:操作MQ的工具
- exchange:路由消息到队列中
- queue:缓存消息
- virtual host:虚拟主机,是对queue、exchange等资源的逻辑分组
- 下载镜像
方式一:在线拉取
1 | |
方式二:从本地加载
上传到虚拟机中后,使用命令加载镜像即可:
1 | |
- 安装MQ
执行下面的命令来运行MQ容器:
1 | |
消息模型
RabbitMQ官方提供了5个不同的Demo示例,对应不同的消息模型
-
基本消息队列(BasicQueue)
-
工作消息队列(WorkQueue)
-
发布订阅(public、Subscribe),根据交换机类型不同分为三种
- Fanout Exchange:广播
- Direct Exchange:路由
- Topik Exchange:主题
官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色
- publisher:消息发布者,将消息发送到队列queue
- queue:消息队列,负责接受并缓存消息
- consumer:订阅队列,处理队列中的消息
基本消息队列的消息发送流程:
-
建立connection
-
创建channel
-
利用channel声明队列
-
利用channel向队列发送消息
基本消息队列的消息接收流程:
-
建立connection
-
创建channel
-
利用channel声明队列
-
定义consumer的消费行为handleDelivery()
-
利用channel将消费者与队列绑定
SpringAMQP
基本介绍
-
AMQP:Advanced Message Queuing Protocol,是用于在应用程序或之间传递业务消息的开放标准。该协议与语言和平台无关,更符合微服务中独立性的要求
-
Spring AMQP:基于AMQP协议定义的一套API规范,提供模板来发送和接收消息。包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层的默认实现
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
案例消息发送
- 在父工程中引入spring-amqp依赖
1 | |
- 在publisher服务中利用RabbitTemplate发送消息到simple.queue队列
1 | |
- 在consumer服务中编写消费逻辑,绑定simple.queue队列
1 | |
案例消息接收
- 在consumer服务中编写application.yml,添加mq连接信息
1 | |
- 在consumer服务中新建一个类,编写消费逻辑
1 | |
WorkQueue模型
- 工作队列,可以提高消息处理速度,避免队列消息堆积
1 | |
Work模型的使用
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
发布订阅模型
- 发布订阅模式与之前区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)
- 常见exchange类型包括
- Fanout:广播
- Direct:路由
- Topic:话题
FanoutExchange
FanoutExchange会将收到的消息路由到每一个跟其绑定的queue
- 在consumer服务声明Exchange、Queue、Binding
1 | |
- 在consumer服务声明两个消费者
1 | |
- 在publisher服务发送消息到FanoutExchange
1 | |
交换机的作用
- 接收publisher发送的信息
- 将消息按照规则路由与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么
- Queue
- FanoutExchange
- Binding
DirectExchange
DirectExchange会将接收到的消息根据规则路由到指定的Queue,因此称为路由模式(routes)
- 每一个Queue都与Exchange设置一个BindingKey
- 发布者发送消息时,指定消息的RountingKey
- Exchange将消息路由到BindingKey与消息RountingKey一致的队列
-
在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
-
利用@RabbitListener声明Exchange、Queue、RoutingKey
1 | |
Direct交换机与Fanout交换机的差异
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解
- @Queue
- @Exchange
TopikExchange
TopikExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,并且以 . 分割
Queue与Exchange指定BindingKey是可以使用通配符
#:代指0个或多个单词
*:代指一个单词
- 在consumer服务中,编写两个消费者方法,分别监听topik.queue1和topik.queue2
- 利用@RabbitListener声明Exchange、Queue、RoutingKey
1 | |
Direct交换机与Topic交换机的差异
- Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
消息转换器
在publisher和consumer两个服务中都引入依赖:
1 | |
配置消息转换器,在启动类中添加一个Bean即可:
1 | |
SpringAMQP中的消息的序列化和反序列化是怎么实现的
- 利用MessageConverter实现,默认是JDK的序列化
- 注意发送与接收方必须使用相同的MessageConverter
初识ES
什么是elasticsearch
-
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
-
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
-
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网
Lucene优势
- 易扩展
- 高性能(基于倒排索引)
Lucene缺点
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
相比与lucene,elasticsearch具备的优势
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
倒排索引
elasticsearch采用倒排索引
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
什么是文档和词条?
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
什么是正向索引?
- 基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
什么是倒排索引?
- 对文档内容分词,对词条创建索引,并记录词条所在文档的信息,查询时先根据词条查询到文档id,而后获取到文档
es与mysql概念对比
-
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中
-
Json文档中往往包含很多的字段(Field),类似于数据库中的列
-
索引(Index),就是相同类型的文档的集合
-
映射(mapping),索引中文档的字段约束信息,类似表的结构约束
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
架构
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
安装ES
部署单点es
- 创建网络
1 | |
- 加载镜像
1 | |
- 运行
运行docker命令,部署单点es:
1 | |
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
在浏览器中输入:http://192.168.150.101:9200 即可看到elasticsearch的响应结果
安装kibana
部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习
- 部署
运行docker命令,部署kibana
1 | |
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
1 | |
查看运行日志,当查看到下面的日志,说明成功
此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果
安装IK分词器
在线安装ik插件(较慢)
1 | |
离线安装ik插件(推荐)
- 查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
1 | |
显示结果:
1 | |
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中
-
解压缩分词器安装包
-
上传到es容器的插件数据卷中
就是
/var/lib/docker/volumes/es-plugins/_data -
重启容器
1 | |
1 | |
- 测试
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
1 | |
IK分词器拓展
-
打开IK分词器config目录
-
在IKAnalyzer.cfg.xml配置文件内容添加:
1 | |
- 新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
1 | |
- 重启elasticsearch
1 | |
总结
分词器的作用是什么?
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
操作索引库
mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
1 | |
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
mapping常见属性
- type:数据类型
- index:是否索引
- analyzer:分词器
- properties:子字段
type常见的有哪些?
- 字符串:text、keyword
- 数字:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下
1 | |
查询、删除、修改索引库
查看索引库
1 | |
删除索引库
1 | |
修改索引库
- 索引库和mapping一旦创建无法修改,但是可以添加新的字段
1 | |
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
文档操作
新增、查询、删除文档
新增文档
1 | |
查看文档
1 | |
删除索引库
1 | |
修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
全量修改
全量修改是覆盖原来的文档,其本质是
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了
1 | |
增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
1 | |
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
RestClient
RestClient操作索引库
-
ES官方提供了各种不同语言的客户端,用来操作ES。客户端的本质就是组装DSL语句,通过http请求发送给ES
- 定义mapping映射的JSON字符串常量
1 | |
- 创建索引
1 | |
- 删除索引
1 | |
- 判断索引库是否存在
1 | |
RestClient操作文档
- 初始化RestHighLevelClient
1 | |
- Hotel类型的对象
1 | |
- 定义一个新的类型,与索引库结构吻合
1 | |
- 查询文档
1 | |
- 删除文档
1 | |
- 修改文档
1 | |
- 批量导入文档
1 | |
DSL
DSL查询语法
- GET /索引库名/_search
- {“query”:{“查询类型”:{“FIELD”:“TEXT”}}}
全文检索查询
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
精确查询
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
地理查询
- geo_bounding_box:根据geo_point值落在某个矩形范围的所有文档
- geo_distance:查询到指定中心点小于某个距离值的所有文档
相关性算分
- TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
- BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平
FunctionScoreQuery
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score与query score如何运算
BooleanQuery
- must:必须匹配的条件,”与“
- should:选择性匹配的条件,”或“
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
搜索结果处理
排序
- elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序
- 排序字段类型:keyword类型、数值类型、地图坐标类型、日期类型等
分页
- from + size
- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
- after search:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
- scroll:
- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用after search方案
高亮
- 在搜索结果中把搜索关键字突出显示
1 | |
RestClient查询文档
全文检索查询
- 全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query部分
1 | |
精确查询
- 精确查询常见的有term查询和range查询,同样利用QueryBuilders实现
1 | |
复合查询
1 | |
排序和分页
- 搜索结果的排序和分页是与query同级的参数
1 | |
高亮显示
- 高亮API包括请求DSL构建和结果解析两部分
1 | |
- 所有搜索DSL的构建,API:SearchRequest的source()方法
- 高亮结果解析是参考JSON结果,逐层解析
数据聚合
聚合的分类
聚合常见的有三类:
-
**桶(Bucket)**聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
**度量(Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
**管道(pipeline)**聚合:其它聚合的结果为基础做聚合
什么是聚合?
- 聚合是对文档数据的统计、分析、计算
聚合的常见种类有哪些?
- Bucket:对文档数据分组,并统计每组数量
- Metric:对文档数据做计算,例如avg
- Pipeline:基于其它聚合结果再做聚合
参与聚合的字段类型必须是:
- keyword
- 数值
- 日期
- 布尔
DSL实现Bucket聚合
1 | |
可以指定order属性,自定义聚合的排序方式:
1 | |
可以限定要聚合的文档范围,只要添加query条件:
1 | |
Metric聚合语法
1 | |
小结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
RestAPI实现聚合
请求组装:
1 | |
聚合结果解析:
1 | |
自动补全
拼音分词器
安装方式与IK分词器一样,分三步:
①解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试
自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
声明自定义分词器的语法如下:
1 | |
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
自动补全查询
-
参与补全查询的字段必须是completion类型
-
字段的内容一般是用来补全的多个词条形成的数组
一个这样的索引库:
1 | |
然后插入下面的数据:
1 | |
查询的DSL语句如下:
1 | |
RestAPI实现自动补全
1 | |
结果解析:
1 | |
数据同步
- elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
ES集群
集群结构
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica)
ES集群相关概念:
-
集群(cluster):一组拥有共同的 cluster name 的 节点
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题
-
主分片(Primary shard):相对于副本分片的定义
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样
集群职责
| 节点类型 | 配置参数 | 默认值 | 节点职责 |
|---|---|---|---|
| master eligible | node.master | true | 备选主节点:主节点可以管理和记录集群状态、决定分片再哪个节点、处理创意和删除索引库的请求 |
| data | node.data | true | 数据节点:存储数据、搜索、聚合、CRUD |
| ingest | node.ingest | true | 数据存储之前的预处理 |
| coordinating | 上面3个参数都为false则为coordinating节点 | 无 | 路由请求到其它节点合并其它节点处理的结果,返回给用户 |
真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求第
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
脑裂问题
- 默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其他候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题
- 为了避免脑裂,需要要求选票超过(eligible节点数量 + 1)/ 2才能当选为主,因此eligible节点数量最好是奇数。对于配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
小结
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
-
路由请求到其它节点
-
合并查询到的结果,返回给用户
分布式新增
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
分布式查询
elasticsearch的查询分成两个阶段:
-
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
-
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
小结
分布式新增如何确定分片?
- coordinating node根据id做hash运算,得到结果对shard数量取余,余数就是对应的分片
分布式查询
- 分散阶段:coordinating node将查询请求分发给不同分片
- 收集阶段:将查询结果汇总到coordinating node,整理并返回给用户
故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
- master宕机后,EligibleMaster选举为新的主节点
- master节点监控分片、节点状态,将故障节点上的分片转移到正常节点,确保数据安全